Planning
Apologies
As you might be able to read in this blog, we’re very busy, well, making the engine. I suppose our aim for a blog every Friday might be a bit out of scope. It’s not like we have a dedicated marketing person or anything… Either way, for now we are sticking to this schedule and we’ll see if we manage to keep to it.
Intro
We’ve started our second sprint in our first block of production now. As you might know from the previous blog post, we have made some structural changes to the team. Raymi stepped down as the product owner and now I (Riko) have been taking over all the production related tasks to help steer the team towards the right direction.
While last block was fully focused on doing pre-production for the project, there were some glaring things left over that we should have worked on during pre-production. We spent most of our time designing out the actual architecture of the engine, but we didn’t do enough on the production front. In terms of planning, pipelines and team organization, we essentially prepared nothing for the production blocks.
My first sprint has been all about fixing this up, so let me walk you through what we’ve done so far.
Figuring out a product backlog
One of the very first things I did early in the first week of this block is setting up a product backlog that we can use to plan ahead for the coming weeks.
For those unaware what that might be, a product backlog is essentially a giant list of features, ordered by priorities. During sprint planning sessions, we can open up the product backlog, look at what features have the highest priority, and set goals for the sprint based around those features.
During pre-production, we made a sheet containing all of the different features that we might want to implement - a feature list. It's split up based on the different feature teams we have in our engine, and each team sorted their features according to MoSCoW standards. MoSCoW is a way of organizing features based on whether the feature Must, Should, Could or Won’t be implemented.
We took that list and build a new sheet around it; the product backlog. It combines all the features in the feature list for clear prioritization.
Here’s what our product backlog looks like currently:
As you can see (if you squint your eyes), it’s quite an extensive list of features - around 200+ features. Each feature has a category (feature team), MoSCoW and priority associated with it.
For the first block of production, we are putting all of our focus on the must features of the engine. Before we move on to any non-must features, all must-features have to at least reach the functional stage of completion.
For context, we have four different stages of completion for a feature. These are generally guidelines for feature completeness and aren’t strictly enforced on all of the features, since features might vary wildly in their definitions.
- First Pass (first stage)
- Has some of its functionality already in prototypes, perhaps already in the actual project.
- It can still be (quite) buggy.
- Doesn't necessarily have proper interfaces yet.
- Functional (second stage)
- Is functioning in the actual project.
- It can still be a bit buggy.
- Has some, if not all, of its interfaces functioning in the engine.
- Presentable (third stage)
- Is fully in use by the actual project.
- There might be some slight bugs left, but nothing should crash anymore.
- Is flexible in its interfaces.
- Polished (final stage)
- No known bugs are left in the feature.
- Handles errors appropriately and doesn't hard crash the project.
- Interfaces are very flexible and compliant with the engine.
For every feature, we also aim to write acceptance criteria. Currently, we haven’t written acceptance criteria for all features yet, but we do have acceptance criteria for all must-features, since those are the ones we are currently focussing on.
In the product backlog, we have also set milestones for each feature throughout this block. They are based on our sprints for this block - which we have four of. We haven’t made a planning for the blocks after this yet, although we do have a general idea for them. We’ll might post a blog about that someday.
Scrum
Once we’ve planned in all the features we want to work on for a sprint, we break them down into “stories”. This is done by the team member that works on the feature in question. They estimate how long it is going to take them, add dependencies if necessary and add it to the related Epic (feature).
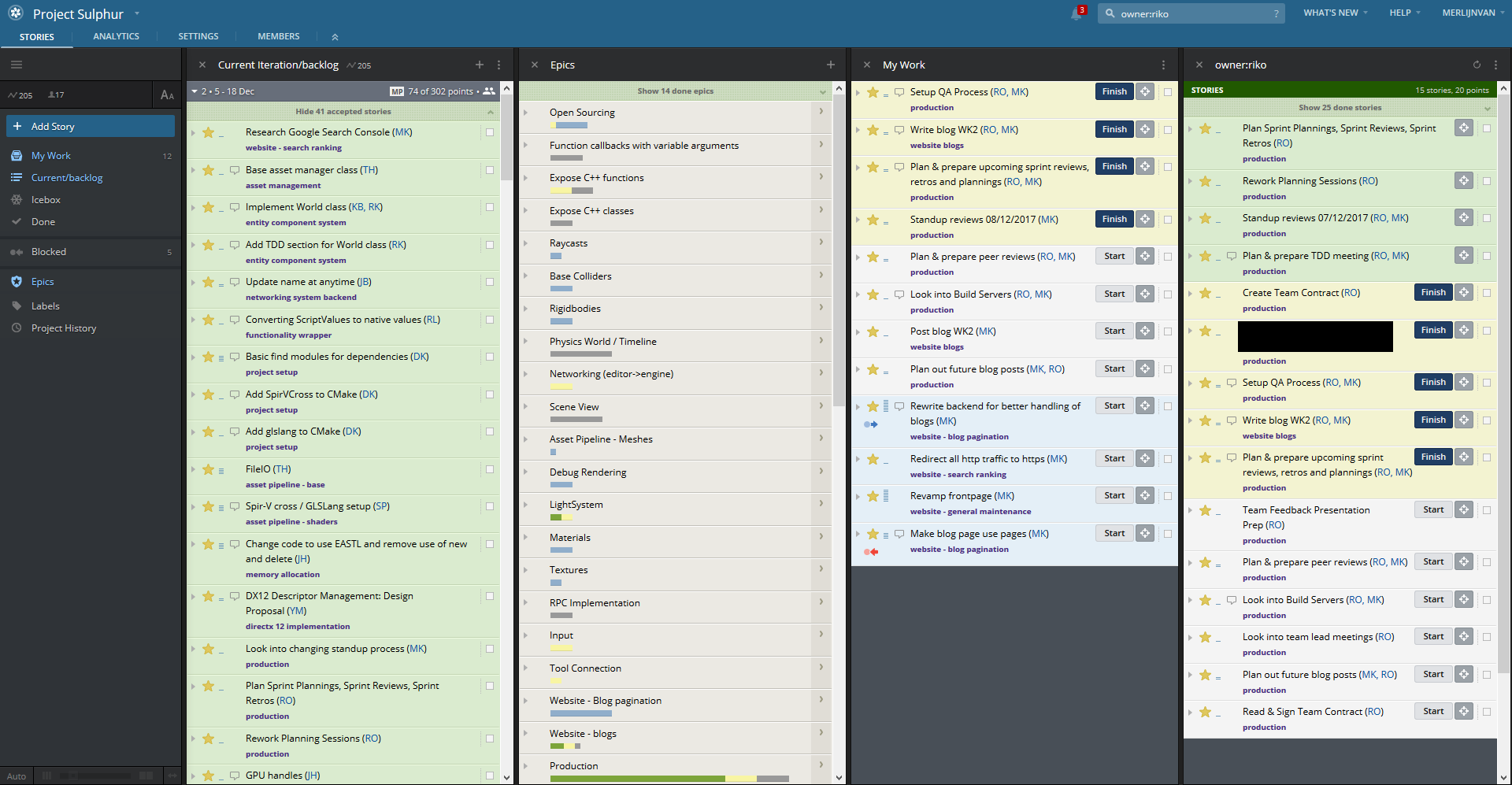
Pivotal, our digital scrum board
As you can see, that results in a LOT of stories. That’s where a scrum board comes into play. There are several ways of managing this, either physically with sticky notes, or digitally, with software such as Trello, Pivotal or JIRA. Although we currently use Pivotal, we will be moving on to JIRA in sprint 3 as an experiment because it has certain interesting features.
Every story has a status, which usually goes through the following workflow:
Unstarted → Started → Finished → Delivered → Accepted / Rejected
This allows us as the production team to quickly and efficiently track everyone’s work on progress on the project.
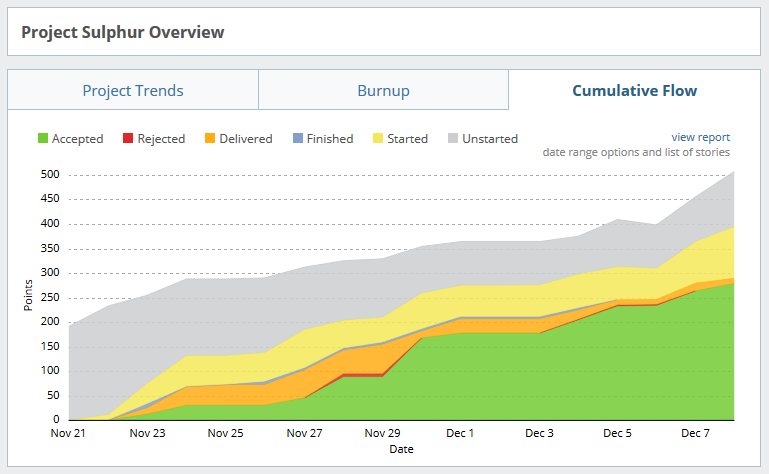
We’ve set 4 points to be about a day of work. So that’s a lot of man hours you’re seeing here!
These are our results right now. As you can see we have a decent velocity but we kept adding stories which prevented us to reaching our goals. In a perfect world, you would plan in a certain number of stories which have a point total equal to your velocity (points you can complete in a single sprint). Of course, that won’t ever happen, but it does allow us to make a pretty accurate planning and have reasonable expectations of the amount of work we can perform in a sprint.
Honestly, there is much more that goes into planning a big project like this, but this blog post is already way too long. Perhaps we’ll write more on another day, perhaps not. For now though, our planning doesn’t allow for any more work on this blog post. Thanks for reading and thanks for following Project Sulphur.
Oh, and we have a GitHub page now! Go to the download page to see it or click right here!