Asset pipeline
In the game industry it’s common practice to do all the work you can up front to reduce the amount of processing that needs to be done at runtime. Before shipping the assets are processed to optimized them for speed, reduce their storage size or both. A good pipeline takes in assets made using 3rd party software and outputs the optimized asset with as little user intervention as possible.
What we aim to support
Our asset pipeline is controlled through our editor. Because our editor is Windows only the asset pipeline will be too. The asset pipeline will be able to export assets for both PC and the PS4 platform. The assets can be exported differently based on the requirements of the platform, but the quality will be identical.
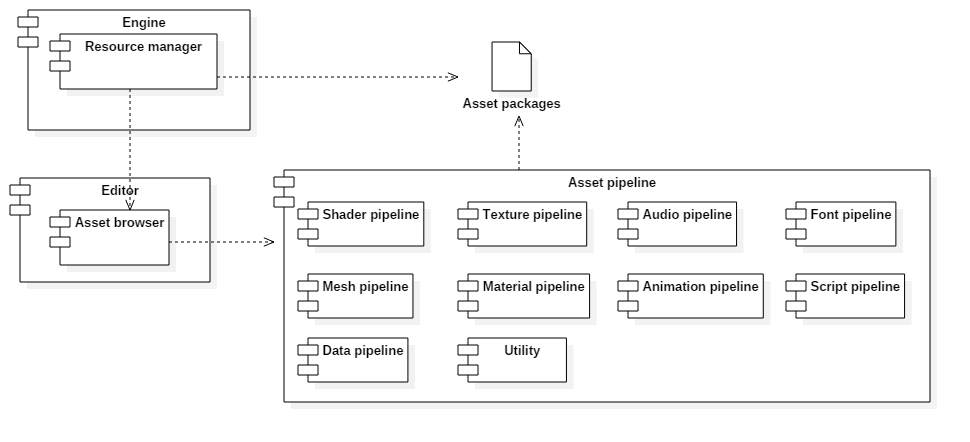
We aim to support all common asset types used in games. Most are pretty straight forward. Their data is extracted from the storage medium of the 3rd party software we are using. The data is optimized for in engine use and stored on disk in a compressed format. Three notable exceptions are textures, materials and shaders. We also want to allow the user to quickly drop in and out of their game for testing. This means that we have to be smart about how we package our assets. We can’t repackage everything every time we want to test our game as this would impact iteration times. We also don’t want to store all files separately as this might impact loading times because of data fragmentation. We aim to have an in-between solution that is both fast and flexible.
Details
Based on the options set in the editor we might generate a full mip chain and/or apply a compression algorithm for textures. Mipmapping will help improve performance and the way our games look at the cost of memory. By compressing the textures we can reduce the runtime memory requirements. By doing both these processes offline we can significantly improve our load times. Our engine will have a shader based material system. This means that we don’t have a predefined material structure. We extract the inputs from the shader using shader reflection. Based on these inputs we create a material that will allow the user to set the parameters to use when rendering a mesh using this shader. The shader reflection step is done offline in the asset pipeline. We expose a couple of default buffers and functions to the user. If the user decides to use these in his shader the asset pipeline can optimize it. One such optimization would be texture packing.
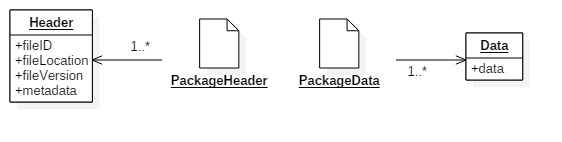
For each type of asset we will have a separate package. The layout and contents of these packages are asset type specific. Each package will consist of two files, a header and the data. The header will contain the id, location, version and a small amount of information about the assets contained in the package. The data file contains the asset. Most of the data will be compressed. Because all assets are stored in one big block of memory, removing or updating the data can create data fragmentation in the package. We try to manage this the best we can by keeping track of the unused spaces and reusing them to store new assets.
Future work
We still have to implement, test and reflect on the asset pipeline before we can make any conclusions. Streaming them in during gameplay is something we have to test as well. We might want to think of more advanced ways to compress the assets and we might want to consider supporting LODs for meshes.